InfGraND: An Influence-Guided GNN-to-MLP Knowledge Distillation
Transactions on Machine Learning Research (TMLR) · January 2026
The Problem
Graph Neural Networks have become the standard for learning on graph-structured data, yet their recursive message-passing mechanism creates computational bottlenecks that limit deployment in latency-sensitive applications. Multi-Layer Perceptrons offer an efficient alternative but sacrifice the structural awareness that makes GNNs effective.
Knowledge distillation - training an MLP to mimic a GNN teacher - has emerged as a promising middle ground. However, existing approaches either treat all nodes uniformly during distillation or discriminate based on prediction confidence. Neither asks the more fundamental question: which nodes are structurally important to the graph itself?
Our Insight
We propose that node importance should be measured by structural influence - quantifying how perturbations to a node's features propagate through the graph topology to affect other nodes' representations.
Our experiments validate this intuition: GNNs trained exclusively on high-influence nodes consistently outperform those trained on low-influence nodes, even when using the same number of training samples. This finding suggests that not all nodes contribute equally to learning, and that structural influence provides a principled criterion for identifying the most informative nodes.
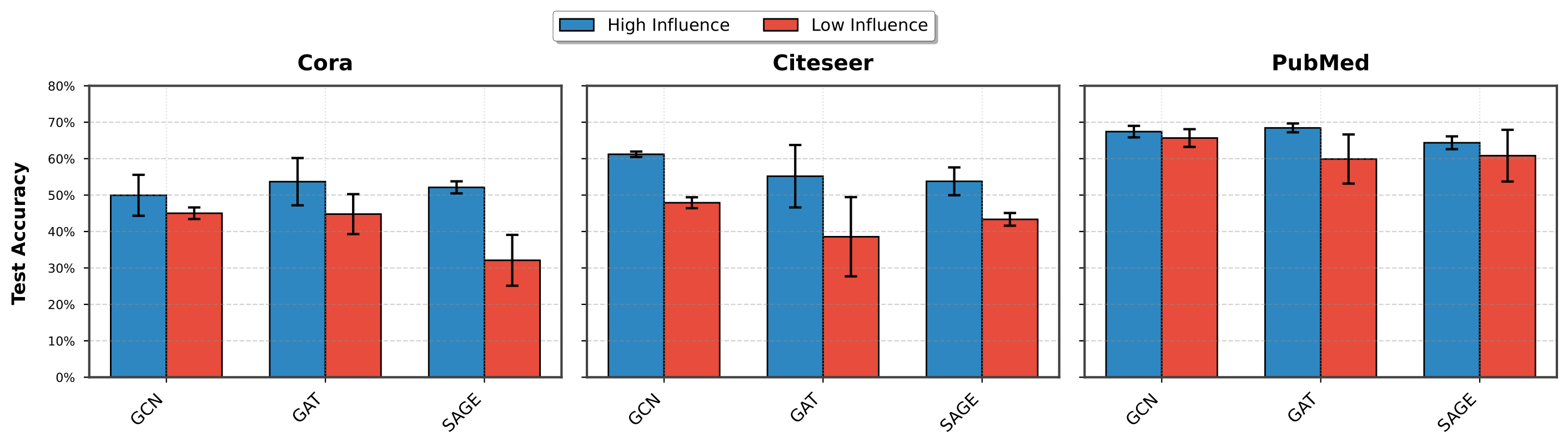 Figure 2: High vs. Low Influence Training Comparison
Figure 2: High vs. Low Influence Training Comparison
Method
InfGraND introduces two complementary mechanisms for transferring structural knowledge from a GNN teacher to an MLP student.
Influence-Guided Distillation. We compute a parameter-free influence score for each node based on cosine similarity between original features and their propagated representations. During distillation, the loss function weights each neighbor's contribution by its influence score, ensuring that high-influence nodes provide stronger supervision signals. This guides the student to learn from the most structurally critical parts of the graph.
Pre-computed Feature Propagation. To provide the MLP with structural context without inference-time overhead, we perform a one-time, offline propagation of node features through the graph topology. The resulting multi-hop neighborhood representations are pooled and serve as enriched input to the student MLP. This computation happens once before training and adds no cost during deployment.
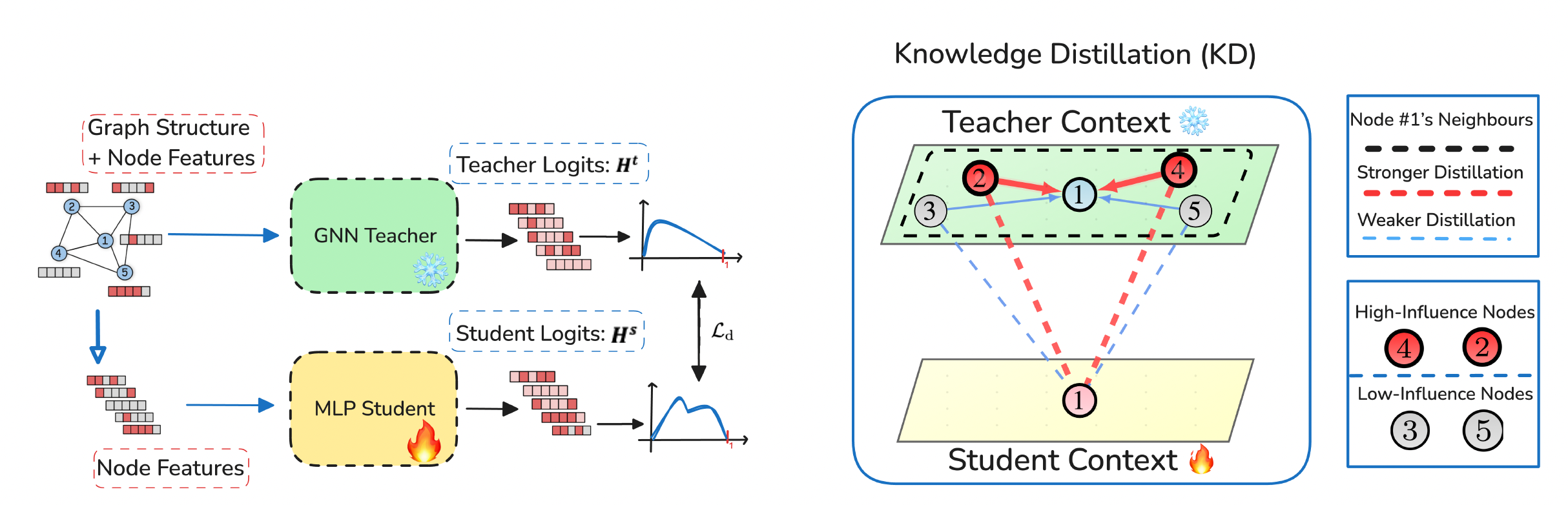 Figure 1: Method Overview
Figure 1: Method Overview
Results
We evaluate InfGraND across seven benchmark datasets in both transductive and inductive settings, using GCN, GAT, and GraphSAGE as teacher architectures. InfGraND consistently outperforms prior GNN-to-MLP distillation methods.
Compared to vanilla MLPs, InfGraND achieves average improvements of 12.6% in the transductive setting and 9.3% in the inductive setting. Notably, the distilled MLPs frequently surpass their GNN teachers in classification accuracy - challenging the assumption that expressive GNNs are inherently superior to MLPs on graph data. Against the strongest baseline (KRD), InfGraND shows gains of 0.9% (transductive) and 3.0% (inductive). On the efficiency front, InfGraND delivers up to 13.89× faster inference than GNN teachers while achieving higher accuracy.
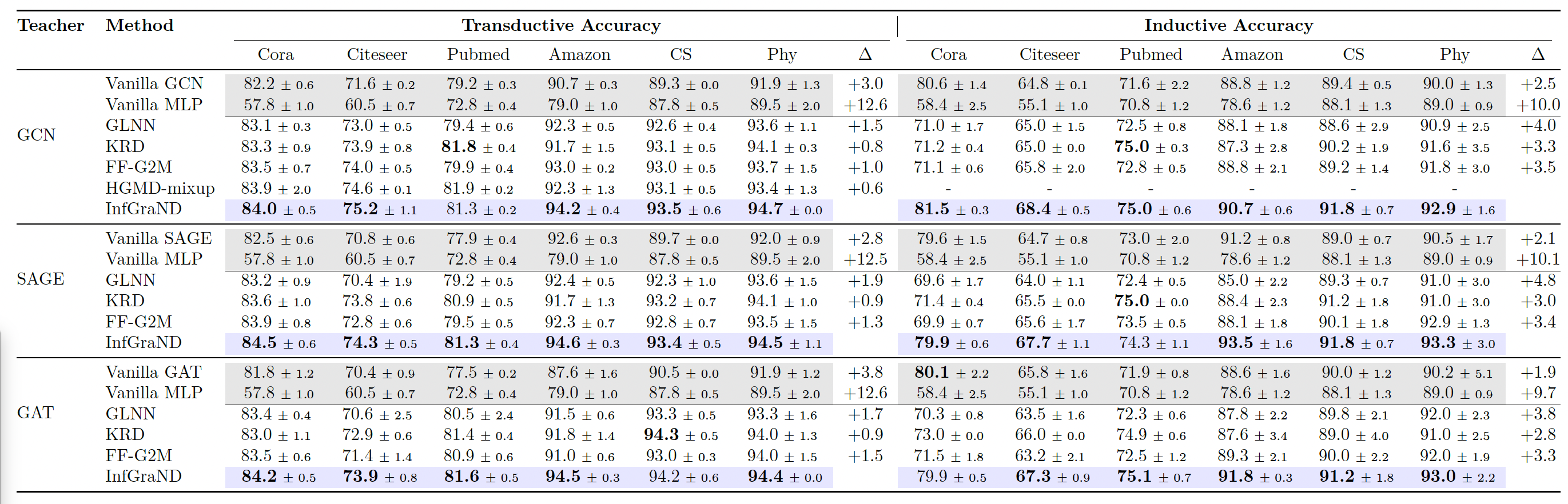 Table 1: Node Classification Results
Table 1: Node Classification Results
Large-Scale Evaluation
To demonstrate scalability, we evaluate on OGBN-Arxiv, a graph with over 169,000 nodes. InfGraND improves over vanilla MLPs by 19.5% (transductive) and 9.5% (inductive), confirming that our approach scales effectively to large graphs.
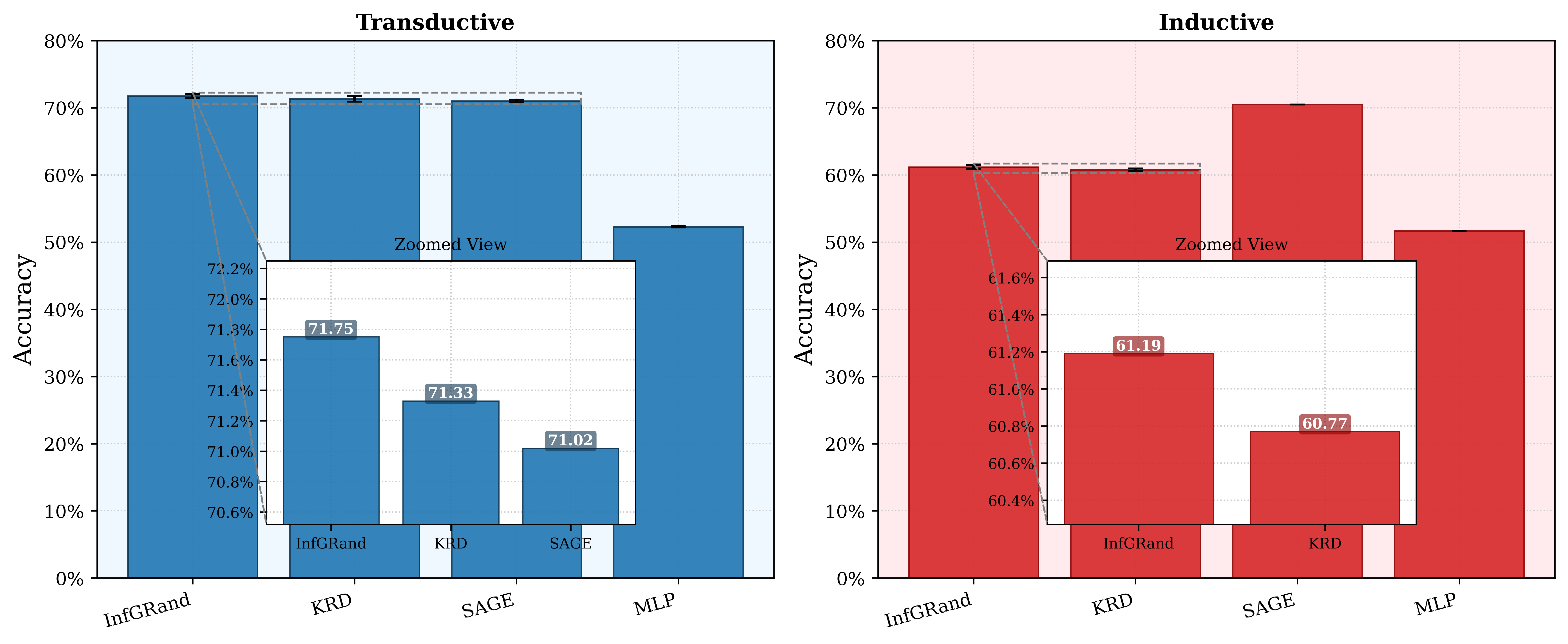 Figure 3: OGBN-Arxiv Results
Figure 3: OGBN-Arxiv Results
Efficiency Trade-off
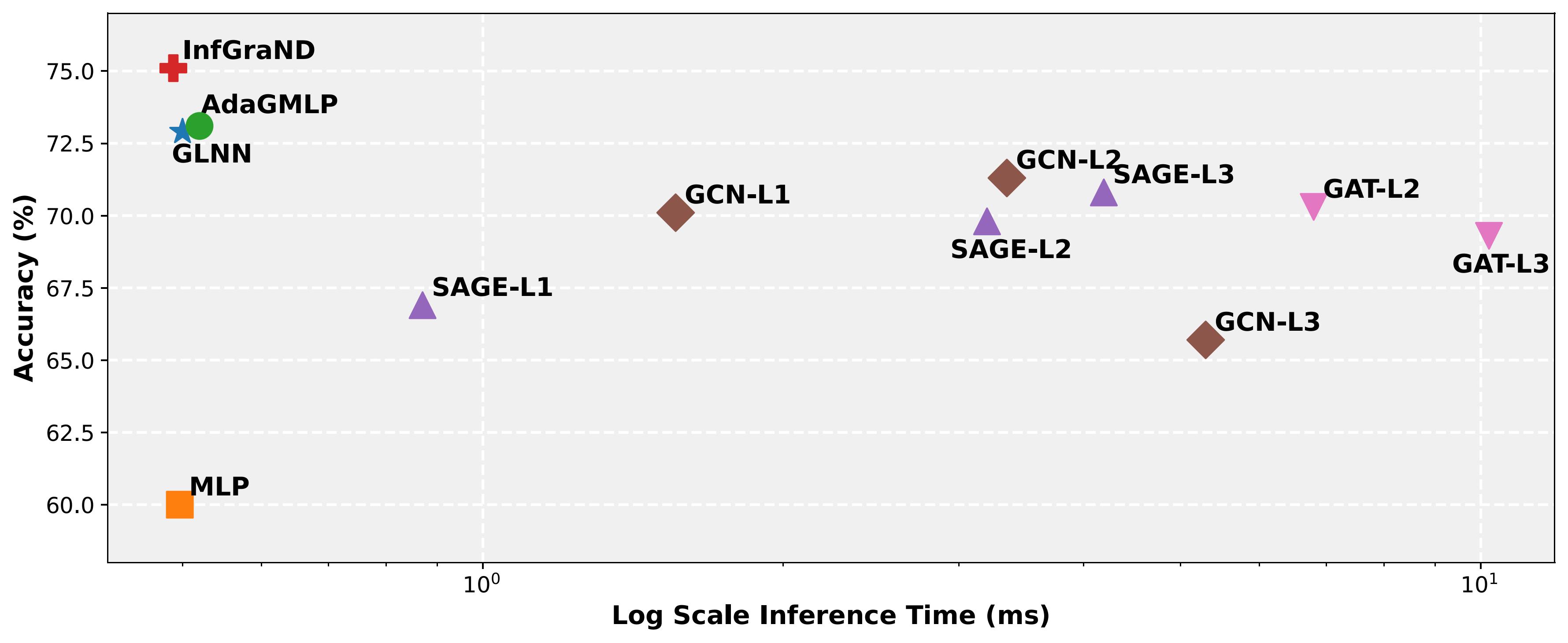 Figure 4: Accuracy vs. Inference Time
Figure 4: Accuracy vs. Inference Time
Citation
If you find this work useful, please consider citing:
@article{eskandari2026infgrand,
title={InfGraND: An Influence-Guided GNN-to-MLP Knowledge Distillation},
author={Eskandari, Amir and Anand, Aman and Rashno, Elyas and Zulkernine, Farhana},
journal={Transactions on Machine Learning Research},
year={2026},
url={https://openreview.net/forum?id=lfzHR3YwlD}
}Acknowledgments
This work was supported by the Connected Minds program through the Canada First Research Excellence Fund (grant #CFREF-2022-00010) and the New Frontiers in Research Fund (grant #NFRFE-2022-00197).